Kłamstwo ma krótką oś Y, czyli jak wykreślić nieprawdę
- Jak uniknąć przekłamań, tworząc wykresy?
- Czym powinniśmy się kierować, decydując się na użycie konkretnego typu wykresu?
- Jak nie przesadzić z ilością danych prezentowanych na wykresie?







Bohater telewizyjnego serialu, doktor House, zwykł mawiać, że wszyscy kłamią. Chcę wierzyć, że ludzie nie są aż tak źli i cyniczni, dlatego pozwolę sobie zmienić tę frazę. Wszyscy mogą kłamać. Niektórzy celowo, inni nieświadomie – efekt jest ten sam. Odbiorca kłamstwa jest wprowadzony w błąd, może wyciągnąć niewłaściwe wnioski – a na ich podstawie podjąć złe decyzje.
Świadomość tego, że możemy paść ofiarą nieprawdy jest szczególnie ważna dziś, w dobie postprawdy i fake newsów, zwłaszcza że nadmiar informacji, którymi jesteśmy bombardowani w każdej minucie, nie pozwala na ich szczegółową weryfikację. Często jedynie prześlizgujemy się wzrokiem po nagłówkach lub zdjęciach, a doświadczenie razem z poglądami dopowiadają resztę. Pół biedy, jeśli dotyczy to jakiejś błahej informacji. Gorzej, gdy damy się w ten sposób zwieść, odczytując kluczowe dla działalności gospodarczej informacje. Rzeczywistość biznesowa sprawia, że cenimy wszelkiej maści syntezy. Zamiast opasłych analiz, wystarczy podsumowanie, najlepiej w formie prezentacji. Zamiast sprawozdania pełnego liczb – raport z wykresami. Najważniejsze informacje przedstawione w formie graficznej wystarczą, aby wyrobić sobie zdanie na dany temat. Przecież jeden obraz zastępuje tysiąc słów. Tylko że wykresy są szczególnie podatne na przeinaczenia. Celowe czy nie – efekt będzie ten sam. Kłamliwy obraz zastąpi tysiąc kłamstw. Jak się przed tym ustrzec? A jednocześnie – jak nie popełnić błędów mogących zwieść innych?
Pułapki wykresów
Zacznijmy od tego, co wydaje się najczęstszym błędem popełnianym przy tworzeniu wykresu, czyli wybór jego typu. Wydaje się, że to nie jest skomplikowane, ale jakże często przy tworzeniu wizualizacji danych autor decyduje się na jakiś typ wykresu bez większej refleksji nad tym, do czego właściwie powinno się go zastosować. Spójrzmy na załączony przykład (rysunek 1).
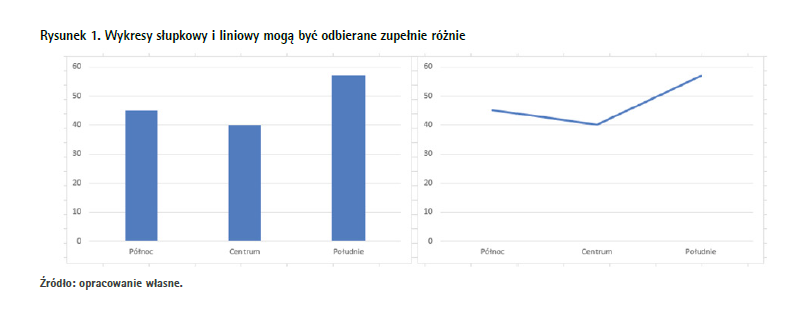
W obu przypadkach na wykresach przedstawiam te same dane liczbowe. Intuicyjnie jednak z tych dwóch wykresów wyciągniemy dwa różne wnioski. W przypadku wykresu liniowego mogę założyć, że dane pomiędzy poszczególnymi wartościami są połączone, zmieniają się stopniowo – maleją i rosną. Z kolei wartości przedstawione na wykresie kolumnowym mogą, ale nie muszą, być ze sobą powiązane. Wykresów liniowych należy zatem używać jedynie dla powiązanych ze sobą chronologicznie danych. W pozostałych przypadkach – pozostańmy przy wykresie kolumnowym. Albo słupkowym (czyli z poziomymi paskami), gdy mamy do przedstawienia sporo kategorii, a chcemy, aby nasz wykres był czytelny.
Jest jeszcze jeden typ wykresu, który jest dość często stosowany, tak jakby komuś zależało na zaciemnieniu, a nie na jak najjaśniejszym przekazaniu informacji. To popularny w ostatnich latach wykres radarowy, widoczny na rysunku 2.
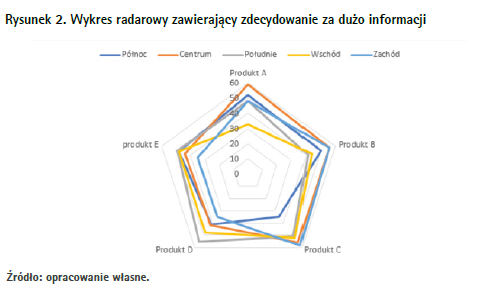
Pokazuje on kilka cech w formie linii lub płaszczyzny łączącej punkty na osiach biegnących promieniście od środka wykresu. Bardzo często pojawia się w podsumowaniach testów psychologicznych, prezentując siłę różnych cech osobowości u badanej osoby. Podstawowy problem z tego typu wykresem jest identyczny jak z wykresem liniowym z poprzedniego akapitu. Łączenie punktów na wykresie radarowym może sugerować, że pomiędzy tymi cechami i zmianami ich wielkości istnieje jakieś powiązanie, tymczasem zazwyczaj go nie ma. Drugim problemem, który często pojawia się w przypadku wykresów radarowych, jest prezentowanie danych zbyt wielu serii. Umieszczenie dwóch przypadków na jednym wykresie może dawać jakieś porównanie. Jeśli jednak jest ich dużo więcej, zamiast czytelnego wykresu otrzymujemy kolorową plamę, bardziej pasującą do muzeum sztuki nowoczesnej niż do biznesowego raportu. W plątaninie linii i osi trudno się zorientować, więc można ukryć tam informację, która niekoniecznie powinna wybijać się na pierwszy plan. Gdyby zamiast wykresu radarowego użyć tradycyjnego kolumnowego, tego typu sztuczki byłyby nieco trudniejsze, choć oczywiście nie niemożliwe, co jeszcze zaprezentuję w dalszej części artykułu.
Jednym z najczęściej stosowanych jest wykres kołowy. Po angielsku nazywa się on pie chart i wydaje się to zrozumiałe, w końcu wiele osób lubi ciasta. Ale nawet najlepsze ciasto w nadmiarze jest niestrawne. Wykresowi kołowemu, np. takiemu jak na rysunku 3, można wiele zarzucić.
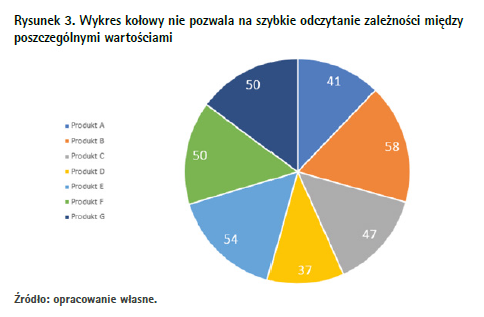
Ludzie nie potrafią poprawnie oszacowywać różnic między kątami, zwłaszcza jeśli nie są znaczące. W przypadku wielu wykresów kołowych mamy do czynienia z więcej niż dwiema kategoriami, co byłoby najczytelniejsze. Im ich więcej, tym trudniej znaleźć różnice między nimi, a to już stwarza pole do nadużyć. Wystarczy ułożyć kategorie na kole nie według wartości. Innym problemem związanym z wykresem kołowym, na którym zaprezentowano sporo danych, jest jego czytelność. Mnogość kolorów, konieczność dodawania legendy, to wszystko sprawia, że odbiorca rozprasza się i nie jest w stanie szybko i poprawnie zinterpretować przedstawionych danych. Zamiast kołowych lepiej stosować wykresy słupkowe lub gałęziowe, a kołowe zostawić sondażom wyborczym – i to dla drugiej tury wyborów prezydenckich, gdy kandydatów jest tylko dwóch.
Czasem jednak przy tworzeniu wizualizacji danych posłuchamy diabełka siedzącego nam na ramieniu i użyjemy wykresu kołowego. Gorzej, jeśli okazuje się, że na drugim ramieniu zamiast aniołka też siedzi diabełek i doradza nam, aby ten wykres przenieść w trzeci wymiar. Spójrzmy na przykład z rysunku 4.
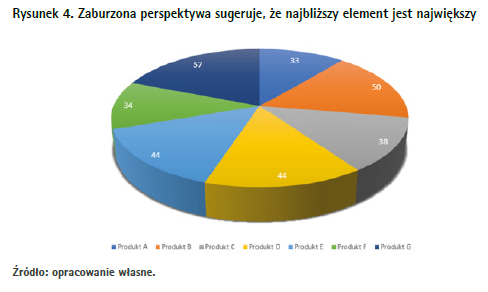
Pojawiają się tu wszystkie problemy wykresu kołowego, ale dodatkowo okraszone niefortunnym imitowaniem przestrzenności. Nadal trudno oszacować kąty na wykresie, ale pochylenie koła dodatkowo zaburza proporcje pomiędzy poszczególnymi jego fragmentami. To trik stosowany przez największych – swego czasu duży i znany producent sprzętu elektronicznego na swojej corocznej konferencji tak ustawił trójwymiarowy wykres, aby sprawić wrażenie, że to do niego należy największy udział na rynku telefonów. Oczywiście wykres był opisany procentami, więc oficjalnie nic nie było przekłamaniem. Ale odpowiedni wycinek koła rzucał się w oczy jako pierwszy, a tym samym można było odnieść wrażenie, że ów producent jest niekwestionowanym liderem, choć konkurencja zauważalnie go wyprzedzała.
Ostatnim typem wykresu, który bywa używany bez związku z charakterem danych, a do tego może zaciemniać informacje, jest wykres powierzchniowy. Powstaje on przez pokolorowanie przestrzeni pod linią łączącą wartości na wykresie liniowym (rysunek 5).
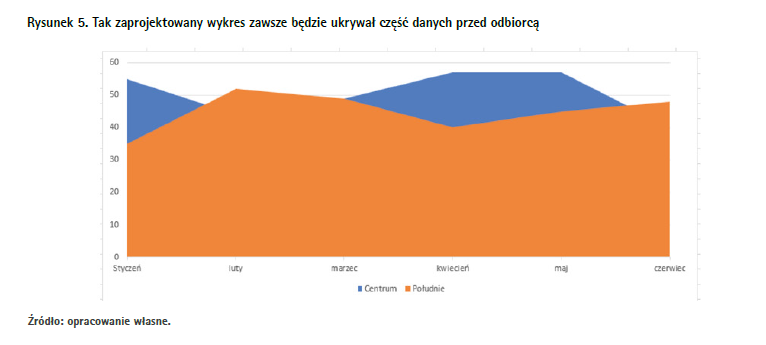
Pomijając problem omówiony na początku, czyli to, że nie dla każdych danych wykres liniowy i pochodne są najlepsze, pojawia się tu jeszcze jedno pole do ukrywania danych. I to dosłownie. Gdy na jednym wykresie umieszczamy kilka wykresów liniowych, jesteśmy w stanie dość swobodnie prześledzić przebieg każdego z nich, bez względu na to, jak kształtują się dane w poszczególnych punktach. Gdy jednak zamienimy to na wykres powierzchniowy, punkty przecięć obu wykresów są miejscami, w których dane chowają się za zasłoną innej serii danych. Widzimy, że jakaś wartość jest niższa od drugiej, ale o ile dokładnie? Czy mamy do czynienia z niewielką korektą danych w dół, czy też z wielkim dołkiem? Nie dowiemy się, o ile nie znajdziemy sposobu na zajrzenie za kolorowe pole. Czasem jako rozwiązanie tego problemu podaje się stworzenie wykresu powierzchniowego w wersji trójwymiarowej, ale to tylko przysparza nowych kłopotów. Perspektywa staje się zaburzona, porównywanie poszczególnych wartości między sobą jest utrudnione, a sens danych znika pomiędzy kolorowymi paskami.
Wykorzystałeś swój limit bezpłatnych treści
Pozostałe 52% artykułu dostępne jest dla zalogowanych użytkowników portalu. Zaloguj się, wybierz plan abonamentowy albo kup dostęp do artykułu/dokumentu.
 Zaloguj się
Zaloguj się








